This issue recommends Plumelog, an easy-to-use Java distributed logging component.
system introduction
- Distributed log system without code intrusion, based on log4j, log4j2, logback to collect logs, set the link ID, easy to query associated logs
Based on elasticsearch as query engine
High throughput, high query efficiency
The whole process does not occupy the application local disk space, maintenance-free; The project is transparent and does not affect the operation of the project
No need to modify the old project, introduce direct use, support dubbo, support springcloud

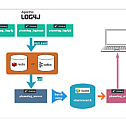
system architecture
- plumelog-core contains a log collector that collects logs and pushes them to kafka, redis, and other queues
plumelog-server is responsible for asynchronously writing logs from the queue to elasticsearch
plumelog-demo Springboot-based use case
Below is the full feature map, the red part is 4.0 content, currently under development

use
First, the server installation
Step 1: Install redis or kafka (redis is sufficient for most companies)
Step 2: Install elasticsearch
Step 3: download the installation package, plumelog – server download address: https://gitee.com/plumeorg/plumelog/releases
Note: UI and server are merged after 3.1, and the plumelog-ui project can be deployed without deployment
Step 4: Configure plumelog-server and start it
Step 5: Background query

More information:
https://gitee.com/plumeorg/plumelog/blob/master/HELP.md
Server configuration file
Plumelog – server/application. The properties, rounding
spring.application.name=plumelog_server server.port=8891 spring.thymeleaf.mode=LEGACYHTML5 spring.mvc.view.prefix=classpath:/templates/ spring.mvc.view.suffix=.html spring.mvc.static-path-pattern=/plumelog/** #值为6种 redis,kafka,rest,restServer,redisCluster,redisSentinel #redis 表示用redis当队列 #redisCluster 表示用redisCluster当队列 #redisSentinel 表示用redisSentinel当队列 #kafka 表示用kafka当队列 #rest 表示从rest接口取日志 #restServer 表示作为rest接口服务器启动 #ui 表示单独作为ui启动 plumelog.model=redis #如果使用kafka,启用下面配置 #plumelog.kafka.kafkaHosts=172.16.247.143:9092,172.16.247.60:9092,172.16.247.64:9092 #plumelog.kafka.kafkaGroupName=logConsumer #解压缩模式,开启后不消费非压缩的队列,如果开启压缩,客户端也要配置开启压缩否则不消费 #plumelog.redis.compressor=true #队列redis,3.3版本把队列redis独立出来,方便不用的应用用不通的队列,如果是集群模式用逗号隔开 plumelog.queue.redis.redisHost=127.0.0.1:6379 #如果使用redis有密码,启用下面配置 #plumelog.queue.redis.redisPassWord=plumelog #plumelog.queue.redis.redisDb=0 #哨兵模式需要填写masterName #plumelog.queue.redis.sentinel.masterName=plumelog #redis单机模式和kafka模式必须配置管理redis地址,redis集群模式不需要配置管理redis地址配置了也不起作用 plumelog.redis.redisHost=127.0.0.1:6379 #如果使用redis有密码,启用下面配置 #plumelog.redis.redisPassWord=plumelog #如果使用rest,启用下面配置 #plumelog.rest.restUrl=http://127.0.0.1:8891/getlog #plumelog.rest.restUserName=plumelog #plumelog.rest.restPassWord=123456 #elasticsearch相关配置,host多个用逗号隔开 plumelog.es.esHosts=127.0.0.1:9200 #ES7.*已经去除了索引type字段,所以如果是es7不用配置这个,7.*以下不配置这个会报错 #plumelog.es.indexType=plumelog plumelog.es.shards=5 plumelog.es.replicas=1 plumelog.es.refresh.interval=30s #日志索引建立方式day表示按天、hour表示按照小时,如果每天日志量超过了500G建议启动小时模式 plumelog.es.indexType.model=day #指定索引建立的时区 plumelog.es.indexType.zoneId=GMT+8 #ES设置密码,启用下面配置 #plumelog.es.userName=elastic #plumelog.es.passWord=123456 #是否信任自签证书 #plumelog.es.trustSelfSigned=true #是否hostname验证 #plumelog.es.hostnameVerification=false #单次拉取日志条数 plumelog.maxSendSize=100 #拉取时间间隔,kafka不生效 plumelog.interval=200 #plumelog-ui的地址 如果不配置,报警信息里不可以点连接 plumelog.ui.url=https://127.0.0.1:8891 #管理密码,手动删除日志的时候需要输入的密码 admin.password=123456 #日志保留天数,配置0或者不配置默认永久保留 admin.log.keepDays=30 #链路保留天数,配置0或者不配置默认永久保留 admin.log.trace.keepDays=30 #登录用户名密码,为空没有登录界面 login.username=admin login.password=adminSecond, client use
The client is used in the project, the non-Maven project downloads the dependency package (
https://gitee.com/frankchenlong/plumelog/releases) under your own lib used directly, package can be used to remove the repeat, then configure log4j can collect log.
logback is recommended, especially springboot and springcloud projects. Note: There are bugs in logback 3.2, please use 3.2.1 to fix it or later.
Introducing Maven dependencies
<dependency> <groupId>com.plumelog</groupId> <artifactId>plumelog-log4j</artifactId> <version>3.4.2</version> </dependency>Configure the log4j configuration file to add the following Appender as an example:
log4j.rootLogger = INFO,stdout,L log4j.appender.stdout = org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target = System.out log4j.appender.stdout.layout = org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} [%c.%t]%n%m%n #kafka做为中间件 log4j.appender.L=com.plumelog.log4j.appender.KafkaAppender #appName系统的名称(自己定义就好) log4j.appender.L.appName=plumelog log4j.appender.L.env=${spring.profiles.active} log4j.appender.L.kafkaHosts=172.16.247.143:9092,172.16.247.60:9092,172.16.247.64:9092 #redis做为中间件 log4j.appender.L=com.plumelog.log4j.appender.RedisAppender log4j.appender.L.appName=plumelog log4j.appender.L.env=${spring.profiles.active} log4j.appender.L.redisHost=172.16.249.72:6379 #redis没有密码这一项为空或者不需要 #log4j.appender.L.redisAuth=123456Describes the client configuration
| field value | use |
appName | User-defined application name |
redisHost | redis address |
redisPort | The redis port number can be configured to end with a colon on host after version 3.4 |
redisAuth | redis Password |
redisDb | redis db |
model | (3.4) redis three models (standalone, cluster, the sentinel) do not configure default standalone |
runModel | 1 indicates the highest performance mode, 2 indicates the low performance mode, but 2 can obtain more information. The default value is 1 |
maxCount | (3.1) The number of logs submitted in batches. The default value is 100 |
logQueueSize | (3.1.2)The buffer queue number size, the default is 10000, too small may lose logs, too large easy memory overflow, according to the actual situation, if the project memory is enough can be set to 100000+ |
compressor | (3.4)Whether to enable log compression. The default value is false |
env | (3.4.2)The environment default is default |
traceID generation configuration
Non-springboot,cloud projects that want to generate traceID need to be added to the interceptor, as follows: (You can also load the filter (
Com. Plumelog. Core TraceIdFilter), if it is timing task, listening class in the forefront of timing task)
@Component public class Interceptor extends HandlerInterceptorAdapter{ @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { String uuid = UUID.randomUUID().toString().replaceAll("-", ""); String traceid= uuid.substring(uuid.length() - 7); TraceId.logTraceID.set(traceid);//设置TraceID值,不埋此点链路ID就没有 return true; } } //注解配置filter示例 @Bean public FilterRegistrationBean filterRegistrationBean1() { FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(); filterRegistrationBean.setFilter(initCustomFilter()); filterRegistrationBean.addUrlPatterns("/*"); filterRegistrationBean.setOrder(Integer.MIN_VALUE); return filterRegistrationBean; } @Bean public Filter initCustomFilter() { return new TraceIdFilter(); }spring boot,spring cloud If sleuth is introduced and feign calls are used between projects, traceId can be passed across services by itself
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> <version>2.2.7.RELEASE</version> </dependency>TraceId is passed across threads
If thread pools are not used, no special processing is required. If thread pools are used, there are two ways to use them (also available in plumelog-demo).
Modified thread pool
private static ExecutorService executorService = TtlExecutors.getTtlExecutorService( new ThreadPoolExecutor(8, 8,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>())); //省去每次Runnable和Callable传入线程池时的修饰,这个逻辑可以在线程池中完成 executorService.execute(() -> { logger.info("子线程日志展示"); });Modifies Runnable and Callable
private static ThreadPoolExecutor threadPoolExecutor= ThreadPoolUtil.getPool(4, 8, 5000); threadPoolExecutor.execute(TtlRunnable.get(() -> { TraceId.logTraceID.get(); logger.info("tankSay =》我是子线程的日志!{}", TraceId.logTraceID.get()); }));
Picture example