Using nodejs implementation, JavaScript is simple, efficient, and easy to learn, saving a lot of time for the development of crawlers and the secondary development of crawler users; nodejs uses Google V8 as the runtime engine, and the performance is considerable; Due to the non-blocking and asynchronous nature of the nodejs language, the performance of the system that is not sensitive to IO-intensive CPU requirements such as running crawlers is very good, and the development volume is less than that of C/C++/JAVA, and the performance is higher than that of the multi-threaded implementation of JAVA and the implementation of asynchronous and Ctrip in Python.
The dispatching center is responsible for the scheduling of URLs, and the crawler process runs in a distributed manner, that is, the central scheduler makes a unified decision on which URLs to capture in a single time slice, and coordinates the work of each crawler, and the crawler single point failure does not affect the overall system.
The crawler has carried out a structured analysis of the web page when crawling, extracted the required data fields, and not only the source code of the web page but also the structured field data when entering the database, which not only makes the data available immediately after the web page is crawled, but also facilitates the accurate content ranking when entering the warehouse.
PhantomJS is integrated. PhantomJS is a web browser implementation that does not require a graphical interface environment, and can be used to crawl web pages that require JS execution to produce content. Perform user actions on the page through JS statements, so that the content of the next page can be crawled after the form is filled and submitted, and the content of the next page can be crawled after the page is jumped after clicking the button.
Integrate the function of proxy IP use, this function is aimed at anti-crawling websites (limited to the number of visits, traffic, and intelligent judgment crawlers under a single IP), you need to provide available proxy IPs, and crawlers will independently choose the proxy IP address that can also be accessed for the source website, and the source website cannot be blocked from crawling.
Configurables:
1). To describe it in regular expressions, similar web pages are grouped together and use the same rules. a crawler system (the following items refer to a certain type of URL configurable items);
2). Start address, crawling method, storage location, page processing method, etc.
3). Link rules that need to be collected, use CSS selectors to limit the crawler to only collect links that appear in a certain position in the page;
3). Page extraction rules: CSS selectors and regular expressions can be used to locate the position of each field content to be extracted;
4). Predefine the js statement to be injected after the page is opened;
5). Cookies set by the web;
6). The rule to judge whether the return of this kind of web page is normal, usually to specify the keywords that must exist on the page after some web pages return to normal for crawlers to detect;
7). The rules for judging whether the data extraction is complete, and selecting several very necessary fields in the extraction fields as the criteria for judging whether the extraction is complete;
8). The scheduling weight (priority) and cycle (how long it takes to recrawl and update) of the page.
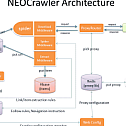
Architecture
 – crawler system插图")
The yellow part of the figure shows the subsystems of the crawler system
SuperScheduler is the central scheduler, the Spider crawler will put the collected URLs into the corresponding URL libraries of various URLs, and SuperScheduler will extract the corresponding number of URLs from various URL libraries according to the scheduling rules and put them into the queue to be crawled.
Spider is a distributed crawler, take out the task from the queue to be crawled by the scheduler for crawling, put the discovered URL into the URL library, and store the extracted content, and divide the crawler into a core core and download, extract, pipeline 4 middleware, in order to be able to easily recustomize one of the functions in the crawler instance.
ProxyRouter intelligently routes crawler requests to available proxy IPs when using proxy IPs.
Webconfig is the backend of web crawler rule configuration.
Run the steps
Prepare the runtime environment
Install the nodejs environment, clone the source code from the git repository to the local computer, open the command prompt in the folder location, and run “npm install” to install the dependent modules;
Redis Server installation (supports both Redis and SSDB, SSDB can be used from the perspective of memory saving, and the type can be specified in the setting.json, which will be mentioned below).
HBase environment, crawled to the web page, the extracted data will be stored in HBase, after HBase is installed, the HTTP REST service will be turned on, which will be used in the later configuration, if you want to use other database storage, you can not install HBase, the following section will talk about how to turn off the HBase function and customize your own storage. Initialize the HBase column cluster in the HBase shell:
create ‘crawled’,{NAME => ‘basic’, VERSIONS => 3},{NAME=>”data”,VERSIONS=>3},{NAME => ‘extra’, VERSIONS => 3}
create ‘crawled_bin’,{NAME => ‘basic’, VERSIONS => 3},{NAME=>”binary”,VERSIONS=>3}
It is recommended to use the HBase REST mode, after you start HBase, run the following command in the bin subdirectory of the HBase directory to start HBase REST:
./hbase-daemon.sh start rest
The default port is 8080, which will be used in the following configuration.
##【Instance Configuration】
In the instance directory, copy an example and rename another instance name, for example, abc.
Edit instance/abc/setting.json
{
/*Note: This is used to explain the configurations, and the real setting.json cannot contain comments */
“driller_info_redis_db”:[“127.0.0.1”,6379,0],/*URL rule configuration information storage location, the last digit indicates the number of Redis databases*/
“url_info_redis_db”:[“127.0.0.1”,6379,1],/*URL information storage location*/
“url_report_redis_db”:[“127.0.0.1”,6380,2],/*Crawl error message storage location*/
“proxy_info_redis_db”:[“127.0.0.1”,6379,3],/*http proxy URL storage location*/
“use_proxy”: false, /*Whether to use proxy service*/
“proxy_router”:”127.0.0.1:2013″,/*In the case of proxy service, the routing center address of the proxy service */
“download_timeout”: 60,/*Download timeout in seconds, not the same as the corresponding timeout*/
“save_content_to_hbase”: false, /* whether to store the scraped information to HBase, so far only tested at 0.94 */
“crawled_hbase_conf”:[“localhost”,8080],/*hbase rest configuration, you can use tcp mode to connect, configured as {“zookeeperHosts”: [“localhost:2181″],”zookeeperRoot”: “/hbase”}, there is an OOM bug in this mode, */ is not recommended.
“crawled_hbase_table”:”crawled”,/*The scraped data is stored in the HBase table*/
“crawled_hbase_bin_table”: “crawled_bin”, /* The captured binary data is stored in the hbase table*/
“statistic_mysql_db”:[“127.0.0.1″,3306,”crawling”,”crawler”,”123″],/* is used to store the analysis results of the crawling logs, which needs to be implemented in conjunction with flume, and is generally not used*/
“check_driller_rules_interval”:120,/*How often to detect changes in URL rules for hot refresh to running crawlers*/
“spider_concurrency”: 5,/*Number of concurrent requests for crawlers to crawl pages*/
“spider_request_delay”: 0,/*The time between two concurrent requests, seconds*/
“schedule_interval”: 60,/*The interval between two schedulers */
“schedule_quantity_limitation”: 200,/*The maximum number of URLs to be crawled by the scheduler to the crawler*/
“download_retry”: 3, /*Number of retries with error*/
“log_level”:”DEBUG”, /*Log Level*/
“use_ssdb”: false, /* whether to use ssdb*/
“to_much_fail_exit”: false, /*whether to automatically terminate the crawler when there are too many errors*/
“keep_link_relation”: false/*Whether the link repository stores the relationship between links*/
}
run
CONFIGURE SCRAPING RULES ON THE WEB PAGE
Debug whether individual URL crawling is OK
Run the scheduler (the scheduler can start one)
If you use proxy IP scraping, start proxy routing
Start the crawler (the crawler can start multiple in a distributed manner)
The following is the specific launch command
1. Run the WEB configuration (see the next chapter for configuration rules)
node run.js -i abc -a config -p 8888
Open http://localhost:8888 in your browser to configure scraping rules in the web interface
2. Test a single page crawl
node run.js -i abc -a test -l “http://domain/page/”
3. Run the scheduler
node run.js -i abc -a schedule
-i specifies the instance name, and -a specifies the action schedule
4. Run Proxy Routing You only need to run proxy routing if you use proxy IP scraping
node run.js -i abc -a proxy -p 2013
The -p here specifies the port of the proxy route, and if it is running natively, the proxy_router and port of the setting.json is 127.0.0.1:2013
5. Run the crawler
node run.js -i abc -a crawl
You can view the output log debug-result.json under instance/example/logs
Redis/ssdb data structure
Understanding the data structure will help you to familiarize yourself with the whole system for secondary development. neocrawler uses 4 storage spaces, driller_info_redis_db, url_info_redis_db, url_report_redis_db, proxy_info_redis_db, you can configure settings.json under the instance, the categories of 4 spaces are different, the key names will not conflict, you can point 4 spaces to a redis/ssdb library, The amount of growth in each space is different, and if you use Redis, it is recommended to point to a DB for each space, and if possible, one Redis for each space.
driller_info_redis_db
Crawl rules and URLs are stored
url_info_redis_db
This space stores the URL information, and the longer the crawl runs, the larger the amount of data will be
url_report_redis_db
This space stores crawl reports
proxy_info_redis_db
This space stores data related to proxy IPs